

The Real Problem Isn’t Prompts, It’s Process
Most teams experimenting with AI tools start with isolated wins: a better code suggestion, a faster draft, a cleaner test. Then they try to chain those wins together and hit friction. The flow becomes fragile, hard to inspect, and even harder to trust.
That’s the problem Attractor is designed to solve. It’s a personal implementation built on the foundation of some genuinely groundbreaking work: StrongDM’s Software Factory and their open-source Attractor project.
StrongDM’s Software Factory is a radical experiment in agentic software development — a system where specs and scenarios drive AI agents that write code, run validation harnesses, and converge on correct behavior without human review. At the center of that system is their Attractor: a non-interactive coding agent that composes language models, prompts, and tools into a directed graph, then traverses it until the work converges. It’s deterministic, observable, and resumable from any checkpoint. The project has spawned community implementations in Python, Go, Rust, TypeScript, Ruby, and more.
This implementation is my own take — built in Kotlin (running on the JVM), extended with multi-LLM support, and adapted for broader workflow orchestration beyond coding tasks alone. The way it names the core problem is borrowed from an unlikely place: dynamical systems theory.
In chaos theory, an attractor is a state that a system naturally gravitates toward over time, no matter where it starts or how turbulent the path. A pendulum settles into rest. Climate patterns cycle through recognizable shapes. The system may wander, but it converges. Attractor, the pipeline engine, applies the same idea to AI workflows: define the goal as a graph, and the engine pulls execution toward it — even across retries, conditional branches, and partial failures.
The pipeline is the attractor. The execution, however messy, converges toward it.
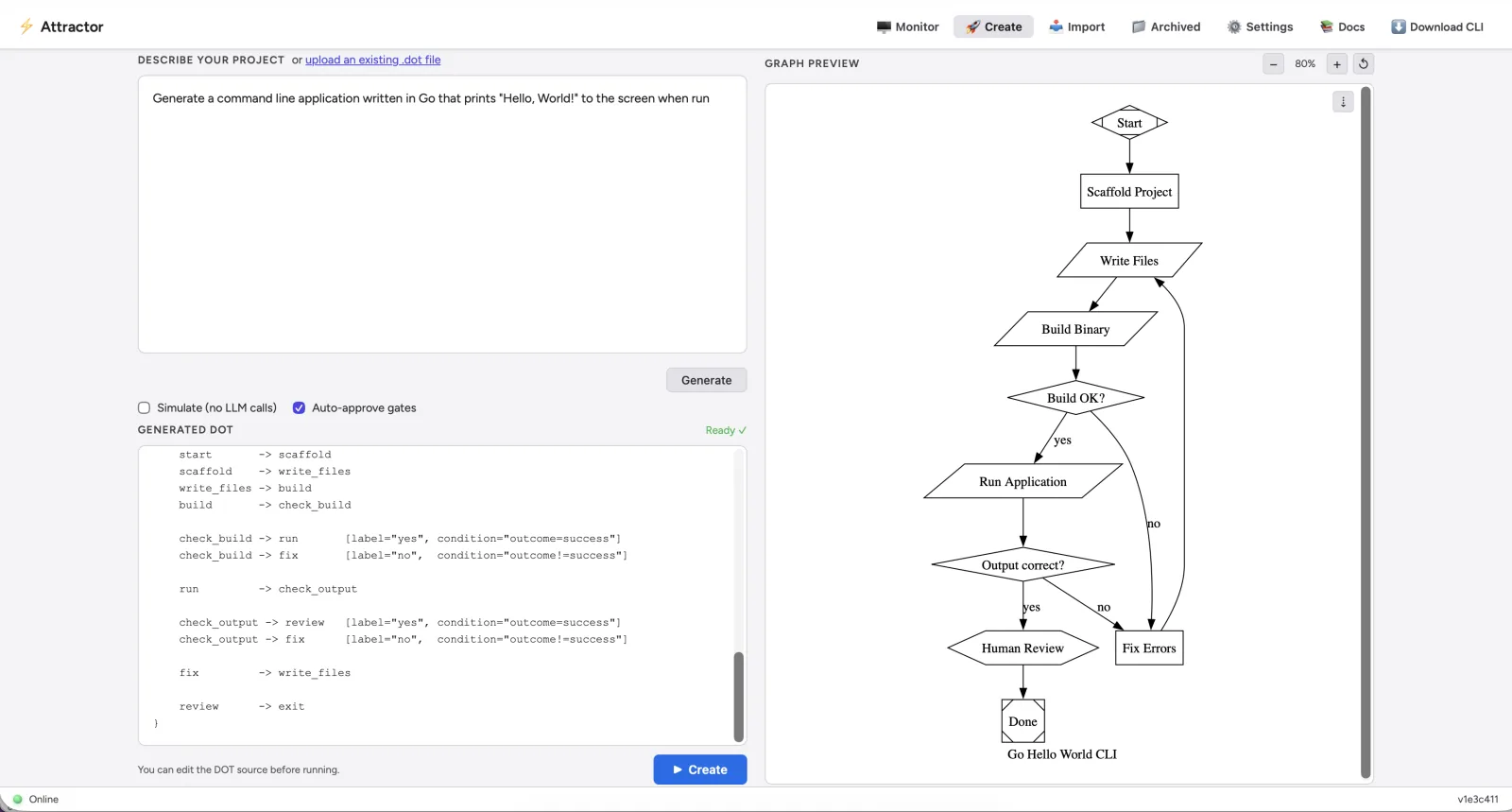
Pipelines as Directed Graphs
Attractor’s central design decision is using Graphviz DOT format as the pipeline definition language. If you’ve used dot for architecture diagrams or dependency graphs, you already know the format. In Attractor, that same notation becomes executable.
Each node in the graph represents a task. Edges represent transitions. The shape of a node tells the engine how to handle it:
| Shape | Behavior |
|---|---|
shape=Mdiamond | Pipeline start |
shape=Msquare | Pipeline exit |
shape=box (default) | LLM prompt node — sends prompt= to a model |
shape=diamond | Conditional gate — routes based on condition= expressions |
shape=hexagon | Human review gate — pauses for interactive approval |
A simple PR automation pipeline might look like this:
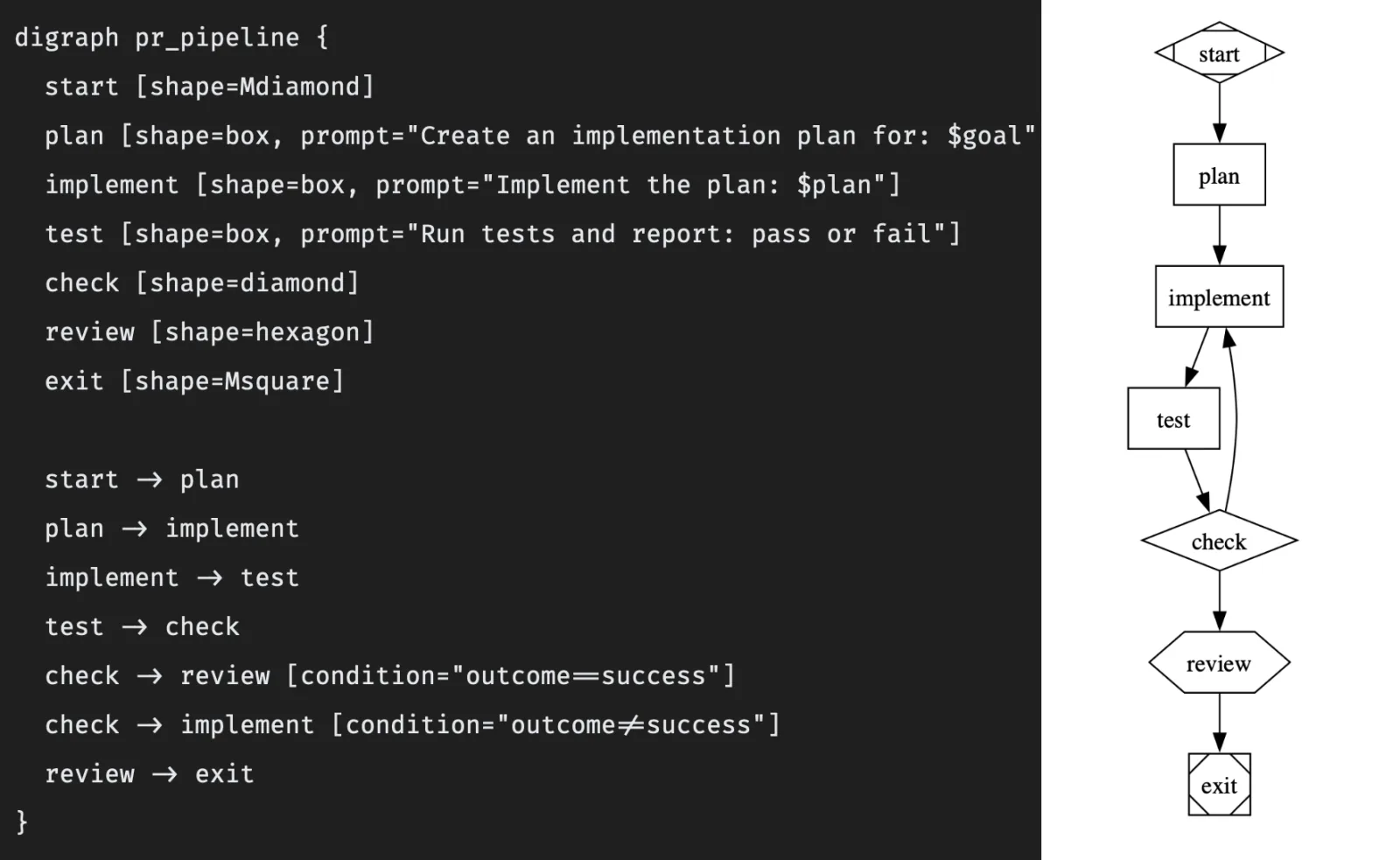
The engine reads this graph, executes each node — dispatching prompts to LLMs, evaluating conditions, pausing at human gates — and routes accordingly. Failed tests loop back to implementation. Success flows forward to human review. When the graph is the contract, the runtime becomes replaceable infrastructure instead of your only documentation.
Real-World Tradeoffs
Worth naming: graph-based orchestration isn’t free.
- Readability degrades as graphs scale. A 50-node pipeline with multiple conditional fan-out paths can become hard to reason about visually.
- Conditional complexity can hide logic bugs. An edge condition that’s almost right is harder to spot than a wrong line of code.
- Human gates increase quality but reduce throughput. That’s a deliberate tradeoff, but it is a tradeoff.
Starting small — one conditional branch, one retry path, one human gate — is the right entry point for new workflows.
Multi-Model as a Governance Pattern
Attractor supports multiple LLM backends: Anthropic Claude, OpenAI GPT, Google Gemini via direct API; Claude Code, GitHub Copilot, and Gemini CLI via subprocess; and any OpenAI-compatible endpoint (Ollama, LM Studio, vLLM) for local models.
The real value here isn’t “more models for variety.” It’s policy-driven assignment. Different steps in a pipeline benefit from different capabilities:
- Planning and decomposition → a strong reasoning model
- Deterministic transformation → a cheaper or local model
- Final review → a stricter human-gated branch
Separating model selection from workflow definition improves cost control and quality at the same time. It also keeps workflows from being silently coupled to one provider’s strengths — or limitations.
Human Gates as First-Class Infrastructure
The shape=hexagon node is worth calling out specifically because it represents something philosophically important: human oversight encoded in the workflow structure, not bolted on as an afterthought.
At a human gate, execution pauses. A developer reviews the output. They can approve, reject, or route execution down a revision path. This is a checkpoint that the process cannot pass without deliberate human action.
In a world where AI agents are increasingly autonomous, the distinction between “notification” and “gate” matters quite a bit. Attractor takes a clear position: some decision points should require explicit human authority, and the workflow should make that requirement unavoidable.
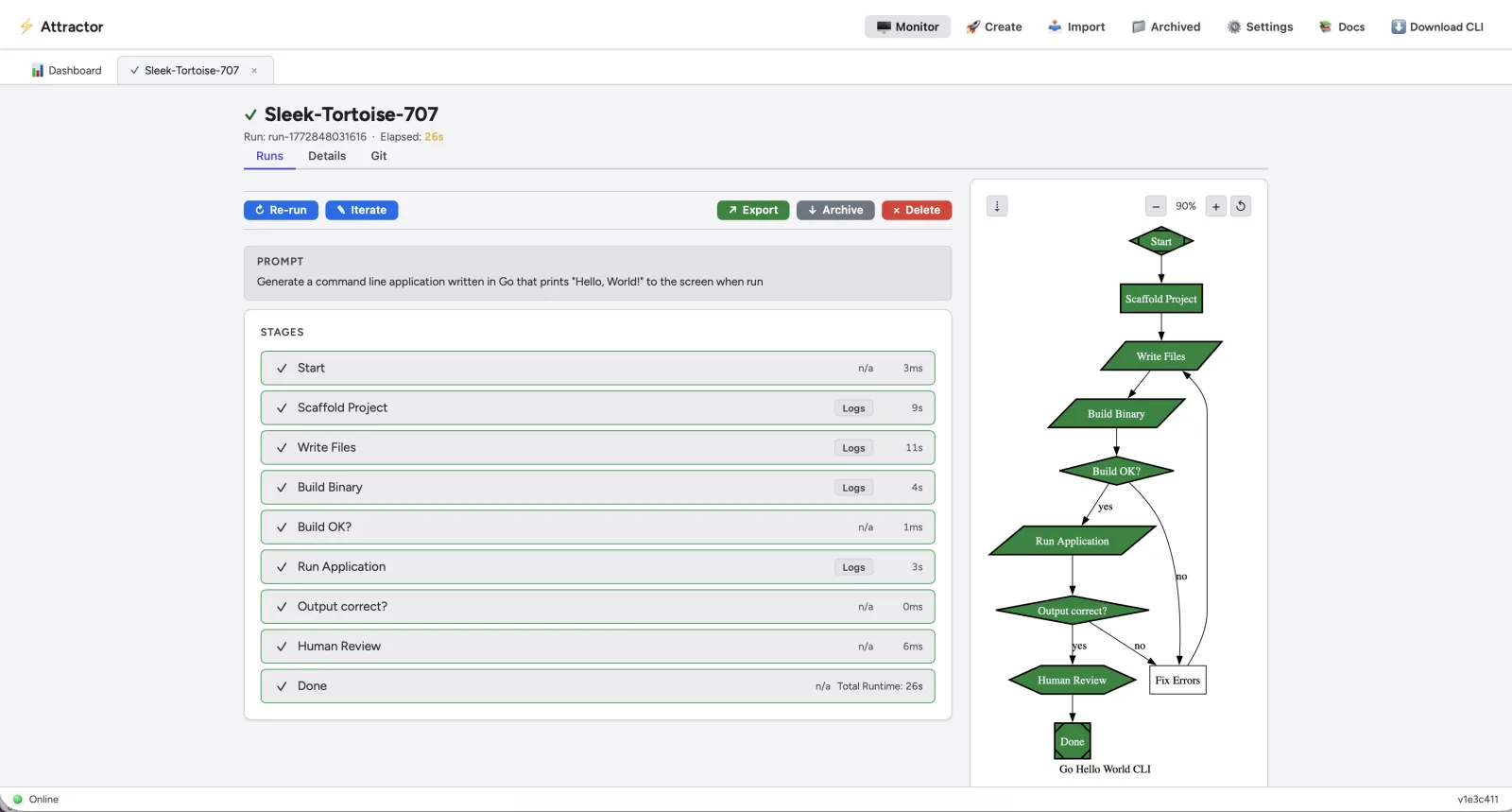
Persistence and Crash Recovery
Long AI pipelines introduce a failure mode that simpler scripts don’t face: you might be twelve steps into a twenty-step pipeline when something breaks. Restarting from step one is wasteful and expensive when each step involves model API calls.
Attractor persists execution state to a database — SQLite by default, MySQL or PostgreSQL for production — and supports resuming interrupted runs from the last successful checkpoint. This is what separates a demonstration from durable infrastructure. Resumability isn’t a nice-to-have; it’s a reliability feature.
A real-time web dashboard at localhost:7070 — powered by Server-Sent Events — lets you watch pipeline execution live, upload DOT files directly from the browser, and monitor concurrent pipeline runs without polling.
The Meta-Story: Built by the Method It Demonstrates
The Attractor codebase and documentation are explicitly AI-generated, with the project itself noting it was inspired by StrongDM’s Software Factory vision: AI agents generate code, run validation, inspect failures, revise, and repeat in a tight loop, while humans define direction and quality standards.
So Attractor is simultaneously a tool for orchestrating AI pipelines and a product of the methodology it implements. That’s a meaningful demonstration. It’s one thing to describe what AI-assisted development at scale could look like. It’s another to have a functional orchestration engine — with a 37-endpoint REST API, real-time dashboard, and multi-database persistence layer — to point at and say: this was built that way.
The appropriate caveat applies: AI-generated code should be reviewed and tested before production use. The point isn’t to skip that discipline; the point is that the process that produces code worth reviewing looks fundamentally different when AI is executing the steps.
Declarative AI Operations
The deeper argument Attractor makes is about a shift in how complex AI processes get defined and operated.
Traditionally, chaining AI steps together meant writing glue code. The workflow logic was implicit — buried in if statements, retry loops, and async handlers. You couldn’t hand someone a diagram of the flow; you handed them a codebase.
Attractor separates what the workflow is from how it gets executed. The graph is the spec. It’s shareable, version-controlled, and readable by people who don’t write Java. When something goes wrong, you debug the graph, not a tangle of procedural code. When you want to modify control flow, you change an edge, not scattered business logic.
That’s declarative AI operations: workflows as first-class, reviewable artifacts, not embedded assumptions. It changes how teams collaborate, how audits happen, and how responsibility is assigned when a pipeline goes wrong.
Attractor is a small project. The architecture it demonstrates is not.
What’s Coming
I’m planning a series of videos to make it easier to get up and running with Attractor. Topics will include:
- Getting Started — installation, dependencies, and your first pipeline
- Configuration — database backends, LLM providers, API keys, and environment setup
- Advanced Usage — conditional branching, parallel execution, human gates, and retry strategies
- Running with Docker — pulling and running the container image built and published via GitHub Actions, with no local JVM or Gradle setup required
I’ll post them here and on the Attractor documentation site as they’re ready, so check back if you want a guided walkthrough rather than diving straight into the docs.
Documentation
The Attractor docs are the best place to start if you want to go deeper — installation guides, configuration reference, pipeline authoring, and more. Fair warning: this project is moving quickly. Features are being added regularly, and while I do my best to keep the documentation current, there may be times where the code is a step or two ahead of the written guides. If something looks off or you can’t find what you need, the GitHub discussions are a good place to ask.
License & Community
Attractor is released under the Apache 2.0 license — free to use, modify, and distribute.
If you run into a bug or have a feature request, please open an issue on the GitHub repository . If you have questions, ideas, or just want to talk through how you’re using it, feel free to start a discussion — that’s what the discussions area is there for.
As AI agents take on more of your workflow execution, which decision points are important enough to encode as explicit gates — and which are you comfortable leaving to prompt luck?