
Panic looks like trying to consume everything at once — every new framework, benchmark, and job requirement — because the field moves fast and standing still feels like falling behind. Dabbling looks like building a toy chatbot, watching a few demos, and telling yourself you’ll go deeper when work calms down.
Neither works. And most engineers cycle between them.
The problem is not motivation. It is strategy. Both patterns optimize for novelty instead of compounding. What actually changes your trajectory is a year of deliberately accumulating judgment, fluency, and proof — in that order, through one sustained body of work.
This roadmap exists to break that cycle: AI/ML Learning Roadmap .
Who This Is For
This is not for someone starting their programming journey. It’s for engineers who already know how to build and run software other people depend on. If you’ve spent years thinking in failure modes and operational cost, understanding what a bad assumption looks like after it’s been in production for six months — that’s the audience.
Experienced engineers have an enormous advantage in this transition that they consistently underestimate. The ML-specific vocabulary and tooling is learnable in months. The underlying judgment that makes someone trustworthy to run production systems takes years, and you have it.
The gap is usually one of confidence, not capability.
Four Phases, One Logic
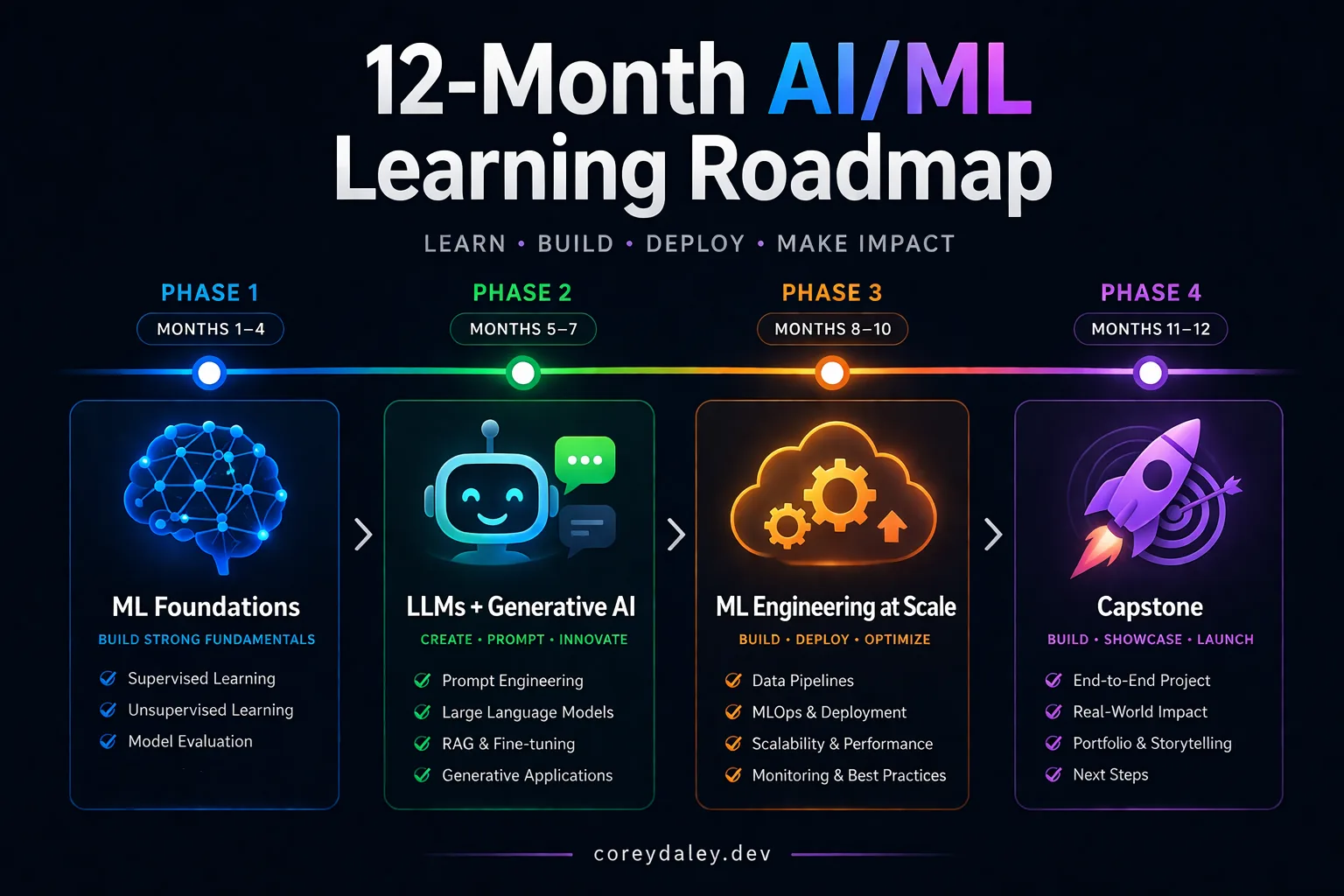
The roadmap runs twelve months across four phases, structured around a single idea: each phase multiplies the value of the one before it.
Phase 1 — ML Foundations (Months 1–4) is about building a mental model before chasing tools. Neural networks, backpropagation, transformers, attention, NLP — enough understanding that terms like tokenization, fine-tuning, and context windows stop feeling like black-box incantations. The field moves quickly, but first principles age slowly. Strong fundamentals are what let you adapt when today’s preferred framework gets replaced by next quarter’s better one.
Phase 2 — LLMs and Generative AI (Months 5–7) shifts from “how this works” to “what can I build with it?” Fine-tuning, RLHF, LLMOps, agent frameworks. Prompt engineering stops being a parlor trick and becomes system design — retrieval, orchestration, evaluation loops, guardrails, the difference between a compelling demo and a product someone can trust. This phase protects against academic drift. By the end, you should have something publicly demonstrable that uses LLMs in a non-trivial way.
Phase 3 — ML Engineering at Scale (Months 8–10) is the part most people skip. Plenty of engineers can get a model to do something impressive on a laptop. Far fewer can explain what should happen after launch: pipelines, deployment, monitoring, drift detection, cost management, operational reliability. This is where AI enthusiasm starts turning into engineering leadership. The sequence is load-bearing — you cannot credibly claim production readiness without it.
Phase 4 — Capstone (Months 11–12) is the conversion layer. By this point you know more and build better, but those gains don’t automatically change your trajectory. The roadmap splits into two tracks: one for engineers targeting a promotion or expanded role at their current company, and one for engineers targeting a new role at an AI company. Both share the same insight: career progress is rarely about raw skill alone. It’s about making skill legible.
The One Design Principle That Matters Most
If there is a single rule worth internalizing above everything else, it’s this: start one project and let it grow with you.
Not twelve experiments. One project — something with real constraints, messy data, or real consequences when it fails. Something close enough to your work that you’ll keep caring after the novelty wears off.
In Phase 1, it’s a sandbox. In Phase 2, it becomes an application. In Phase 3, it becomes a system. In Phase 4, it becomes proof.
That continuity matters because it’s what produces a real story at the end: here is the problem I picked, here is how my approach evolved, here is what I learned when theory met production constraints. A folder full of disconnected experiments doesn’t produce that story. One sustained project does.
The blog cadence in the roadmap is one post per month, timed to learning milestones. That structure exists to keep output grounded in genuine depth — there is a real difference between “I finished the deep learning specialization” and a post that walks through implementing backprop from scratch and explains where your intuition broke down. Writing forces you to find the gaps that reading lets you paper over.
The Investment Frame
Some of this roadmap is free — the Anthropic Academy courses, Google Colab, Kaggle, Ollama, and most of the core tooling cost nothing. Some of it costs money: a course subscription, an AI coding assistant, occasional cloud compute.
Money is not actually the hardest part for most senior engineers. The real cost is consistency over twelve months — the weeks when work is hectic, the temptation to consume news instead of building, keeping a side curriculum running while a full-time job keeps trying to reclaim your attention.
Before spending anything, check your employer’s learning budget. Many companies offer $1,000–$5,000 in annual learning stipends that frequently go unused. This roadmap can often be funded entirely by your employer. It’s worth asking before paying out of pocket.
Your AI Assistant Is a Personal Tutor
One of the best uses of an AI assistant during this year is not coding faster. It’s learning better.
When a concept in a paper doesn’t click, ask it to explain the intuition differently. Ask it to compare two architectures and walk through the trade-offs. Ask it to quiz you on what you just read. Ask it to argue the other side when you’re too attached to your first design. Ask it to pressure-test your evaluation plan before you build it.
An always-available resource that meets you exactly where you are, at 11 PM when you finally have thirty minutes, with no office hours and no judgment for asking the same question three different ways — that’s a genuinely novel learning condition. Use it that way.
Where to Start
The full AI/ML Learning Roadmap covers everything: course recommendations for each phase, portfolio milestones, blog post topics, hardware recommendations, cloud resources, tooling, and the capstone split. Start with the Pre-Roadmap section — the Anthropic Academy courses are free and give you a working mental model before you get into deep learning fundamentals.
One practical note: the specific resources in this roadmap will need to evolve. The AI landscape moves fast enough that some course recommendations will be outdated before you reach Phase 3. The phases and the sequence are durable. The specific vehicles for getting through them are not.
If the roadmap looks like too much to hold in your head at once, that’s normal. Start smaller than your ambition. Pick the first course. Pick the project. Pick the first monthly artifact you want to publish or share internally. Don’t wait for the perfect stack, the perfect hardware, or the perfect study plan.
Momentum compounds. Elegant preparation doesn’t.
A year from now, which would you rather have: a folder full of half-finished experiments, or one project that grew into real proof?